




In this post I will describe how to easily create your own webbrowser with FPC in Lazarus IDE using Gecko engine.
About Gecko
Gecko is a web browser engine used in many applications developed by Mozilla Foundation and the Mozilla Corporation (notably the Firefox web browser including its mobile version and their e-mail client Thunderbird), as well as in many other open source software projects. Gecko is free and open-source software subject to the terms of the Mozilla Public License ver.2.
From the outset, Gecko was designed to support open Internet standards. Some of the standards Gecko supports include:
- CSS Level 2.1 (partial support for CSS 3)
- DOM Level 1 and 2 (partial support for DOM 3)
- HTML4 (partial support for HTML5)
- JavaScript 1.8.5 (full ECMAScript 5.1 support)
- MathML
- RDF
- XForms (via an official extension)
- XHTML 2.0
- XML 2.0
- XSLT and XPath, implemented in TransforMiiX
More about Gecko you can read on it’s Wikipedia Page, Gecko at Mozilla Developer’s Network and Gecko at MozillaWiki.
Let’s Start
First of all we need additional VCL component for Lazarus IDE for our browser. It’s called GeckoPort and you can download it here: GeckoPortV1 [380 kB]
After download, unpack this archive to your “lazarus/components” directory:
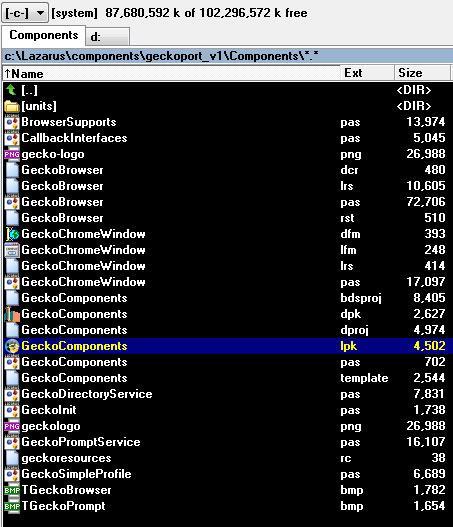
And open GeckoComponents.lpk with your Lazarus IDE.
Be sure that you use 32 bit Lazarus IDE! If it’s 64 bit – XULRunner will not work and Lazarus will give us exception message while compiling about missing nspr4.dll library. Like this:
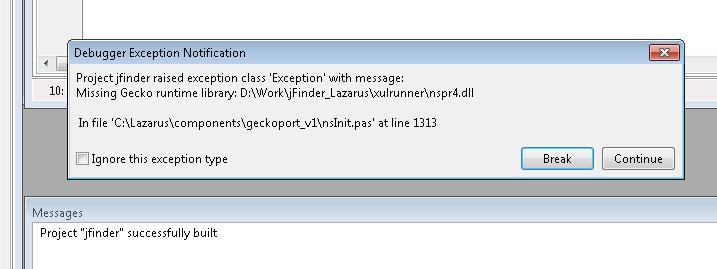
For this project I use Lazarus 1.2.4 i386-win32:

So, after opening GeckoComponents.lpk in Lazarus you will see a window like this:
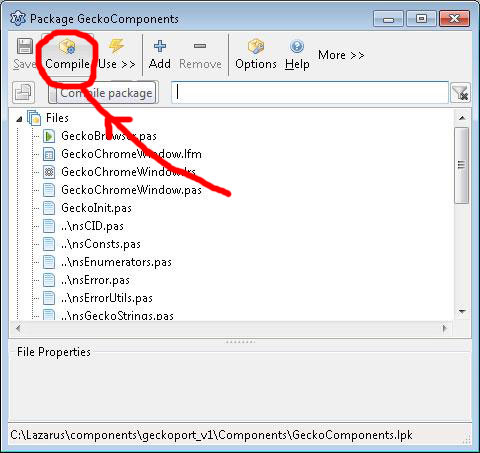
Click “Compile” and wait till it’s done…

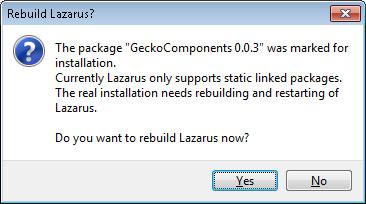
After the package was compiled we need to install it by clicking “Use -> Install”:

And “Do you want to rebuild Lazarus now?” – “Yes”:
That’s it. Now we’ve got 2 new components in our library to build Gecko Webbrowser:
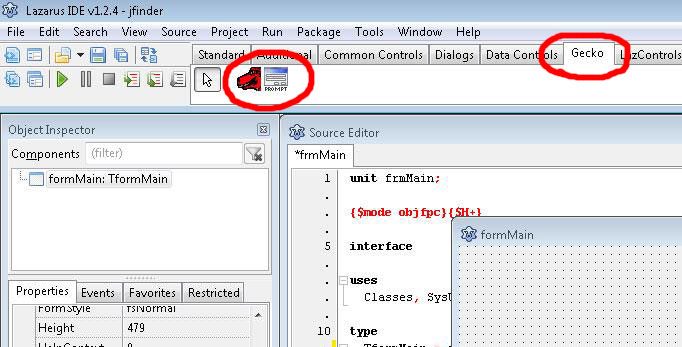
But GeckoPort doesn’t realize Gecko Engine. It’s just an interface to connect engine to the IDE. So now we need to get Gecko engine itself so we can include it in our Lazarus project. It’s called XULRunner and you can find it here – XULRunner ver.1.9.2 or directly from here XULRunner v.3.6.26 for Win32 [11 MB].
Creating Lazarus project with Gecko Browser
Create a new Project in Lazarus, save it on your local disc and unpack XULRunner archive directly in your project’s folder:
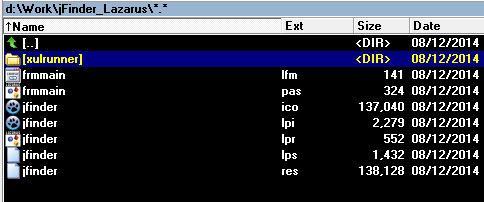
Now go to the Lazarus IDE and click on “View Project Units” button in out project. In the window make double click on out project’s .lpr file to edit it’s code.

In it we need to add “Math” unit in “uses” section and in the main program section (right after “begin”) “SetExceptionMask” command to disable all floating point exceptions which can occure in XULRunner.
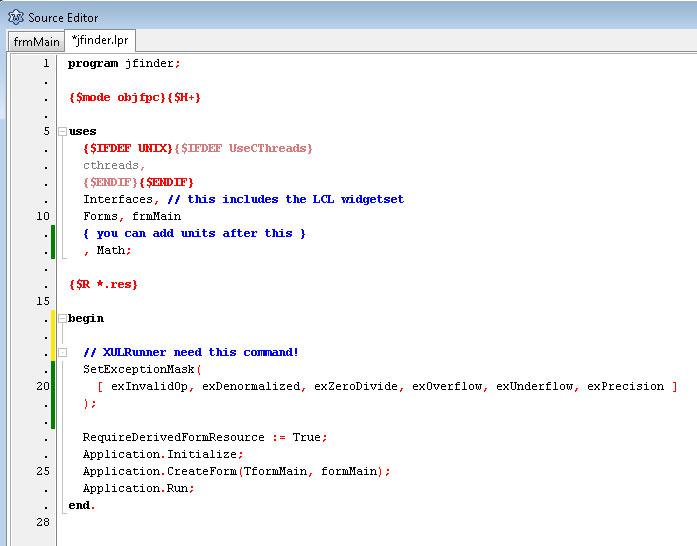
SetExceptionMask (
[ exInvalidOp, exDenormalized, exZeroDivide, exOverflow, exUnderflow, exPrecision ]
);
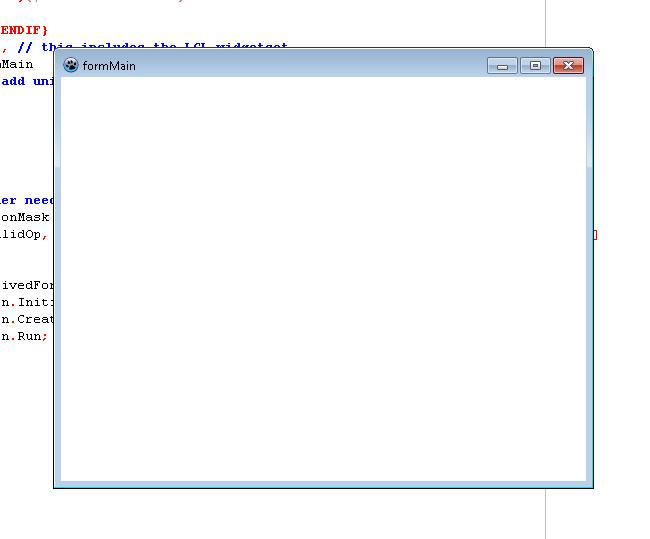
Now, put TGeckoBrowser component on your form (make it Align = alClient) and start your application. If you see just a blank white form – all works fine.

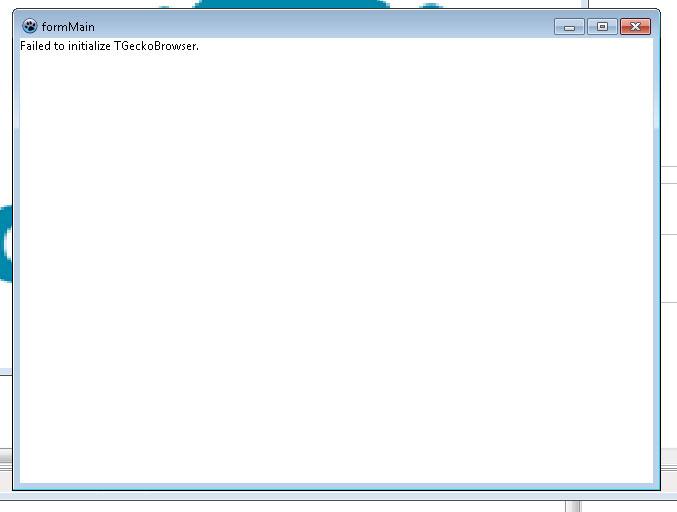
If something goes wrong (for example you use 64bit Lazarus, etc.) you will see “Failed to initialize TGeckoBrowser” message in your window:
Opening WebPages
Let’s now try to load some webpage using our browser. Just call TGeckoBrowser’s LoadURI method in any place of your program (I call it on FormCreate event):
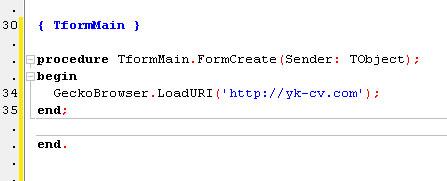
GeckoBrowser.LoadURI('http://yk-cv.com');
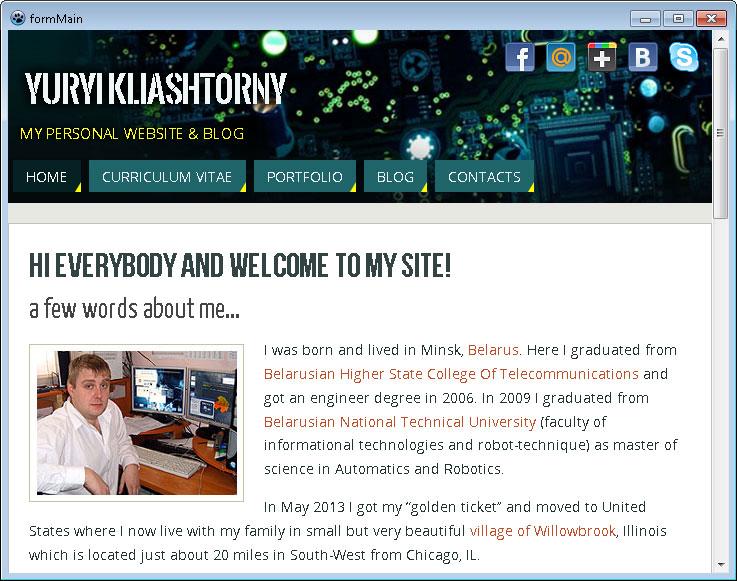
And start your application. If there is no problems with internet, you will see something like this:
Now you can add some additional functionality to your webbrowser like “Go Back” and “Go Forward” buttons or add a progress bar to see how page loads (TGeckoBrowser provides all such methods and events “from the box”).
But I’ll tell you how to make a screenshot of your webbrowser window.
To save a screenshot of your browser’s window we need to wait till page is totally loaded. The best way to determine it is to listen to the “OnDOMLoad” event of TGeckoBrowser object.
When this event is “fired” we can to save the canvas of GeckoBrowser to the file with next function:
procedure TformMain.GeckoBrowserDOMLoad(Sender:TObject; aEvent:TGeckoDOMEvent);
begin
TakeScreenshot('SomeScreenshotName');
end;
procedure TformMain.TakeScreenshot(fileName: string);
var
SShot : TPicture;
SRec, DRec : TRect;
begin
try
SShot := TPicture.Create;
SRec := Rect(0, 0, GeckoBrowser.Width, GeckoBrowser.Height);
with SShot.Bitmap do
begin
Width := GeckoBrowser.Width;
Height := GeckoBrowser.Height;
DRec := Rect(0, 0, Width, Height);
Canvas.Lock;
Canvas.CopyRect(DRec, GeckoBrowser.Canvas, SRec);
Canvas.Unlock;
end;
SShot.SaveToFile(fileName + '.png', 'png');
finally
SShot.Free;
end;
end;
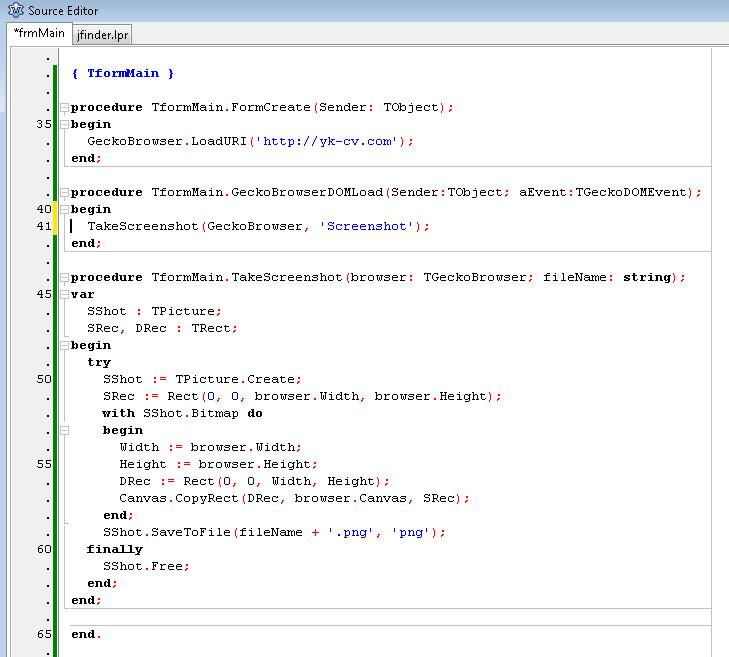
Now you can explore internet and save the screenshots of all the pages you visit.
The only pretty bad thing about TGeckoBrowser, is that it hasn’t got any possibility to access the HTML code of the page directly ![]() It loads the page from internet and converts it into the DOM structure “on the fly”. But… If you can understand how to work with this DOM structure, you will find it very usefull and very easy to analyze and even transform.
It loads the page from internet and converts it into the DOM structure “on the fly”. But… If you can understand how to work with this DOM structure, you will find it very usefull and very easy to analyze and even transform.